And thanks to our sponsors to make it possible!






































































And thanks to our sponsors to make it possible!
So since this morning, I can’t stop thinking about it. And I have the feeling we need to talk. Urgently.
Why we still need hackathons
When I talk to agencies or bigger ecommerce companies about hackathons and the value they bring, it isn’t easy to understand for them. We don’t measure the amount of PRs or lines of code. We have no rules what to do, our attendees don’t have to accomplish anything.
So why is it worth still supporting and organizing hackathons, when we have Contribution Days, organized by Magento itself and its Community Engineering Team?
Please don’t misunderstand me, the idea behind the Contributions Days is great. And the Engineering Team is doing an amazing job but they can’t care for the community. And I understand, that for an agency a Contribution Day and contributing developers are huge marketing tools.
But for freelancers, beginners, junior developers and alike a Contribution Day might be scary. Not the Engineering Team or the community, but the pressure to deliver. Of course, there is no open pressure, no punishment for underperforming, of course not. And I know, the team members are extremly nice and kind, they really are! But still especially for beginners doing their first steps in our community on a contribution day is tough.
And now?
A Hackathons is about the people. A Contribution Day is about Magento.
We need a balance, a place and room for contributions and a time and place for hacking, coding, learning, talking, laughing, meeting friends, finding friends, falling in love, making memories without pressure and goals. All the things that make our community so unique and lovable.
So my dear, dear community, please, don’t give up on hackathons. These small events far away from business, facts and figures.
I don’t want us to talk about the hackathons as something from the past with sparkling eyes how great the time was. We sound like old people:
“Do you remember…?”
“Ah a long time ago we did….”
“…”
I believe that every new member of our community should have the possibility to enjoy the same valuable moments as we “oldies” did.
I am sure that there is room for both and there is a desperate need for both. I am convinced losing the hackathons is a big loss for our community.
To Magento and the Magento Community Engineering Team: Please, don’t see the hackathons as a rival to the Contribution Days, see them as a complement, as one puzzle piece of many for a healthy community.
To agencies: send your developers (seniors and juniors), send your PMs, support local hackathons and let your team attend. Or even better, organize one.
To Magento veterans: please, still support and attend hackathons. Don’t give up on on them.
The topic is really important to me, so it would be great, if it could be the beginning of a discussion, that reaches many different people. So leave a comment, share and discuss on Twitter and tell me what you think.
]]>But there are people out there who wouldn’t accept that. In this case: Daniel Fahlke. So he started even more advertising than we did. And he did good. He asked again and again ifpeople said “I think about it” until they agreed (or denied). In the end we didn’t have 24 posts, but a lot more, than we anticipated in the end of November.
To all our authors a big thank you for filling one of the windows. And an even bigger thank you to Daniel for collecting and connecting all the people!
Photo by freestocks.org on Unsplash
]]>Our client’s expectations were defined clearly: Customers in the web shop shall be able to customize a rack consisting of a larger range of different parts to their individual needs by means of the configurator. After choosing the right edition (light, intermediate, or heavy duty) for the pallet rack he shall be able to define the number of rack bays and the number of shelves per rack bay. Mandatory supply like nuts and bolts shall be included automatically and upon request also optional extra parts like anti-ramming protection corners.
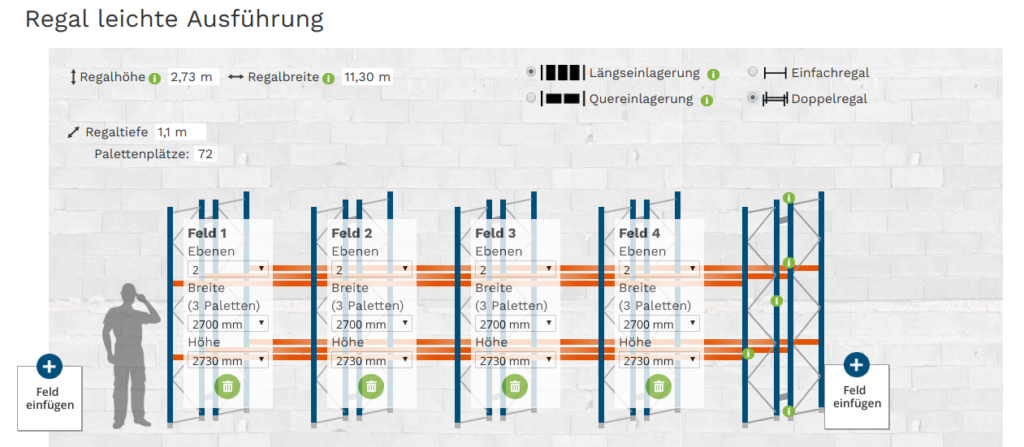
After finishing configuration the customer shall be able to add the individually assembled rack to cart and find it there as one entity instead of a chaotic hotchpotch of parts. Otherwise it would be unreasonable for the customer to select all the right parts in the accurate quantity to remove a complete rack from a cart full of parts belonging to two or more racks for example. And even if a customer would take on this busywork it could still happen that in the end there remains a selection of parts in the cart that do not fit together and would not add up to a complete and viable but to a completely insecure rack. This is what had to be avoided.
As our task was to develop a configurator for the individual assembling of products, it was not an option to rely on pre-defined bundled products from the beginning. But with regard to the three editions of racks in the web shop there was the possibility to define a complex grouped product for each of the payloads as base for the configurator. So there would be one configurator on each of the three product pages. But in the end only the contained parts of a grouped product, i.e. simple products, are added to cart. And in the case of an individually configured pallet rack this would be quite a lot of parts. And as soon as more products are added to cart it would no longer be apparent which parts belong to the rack and which don’t.
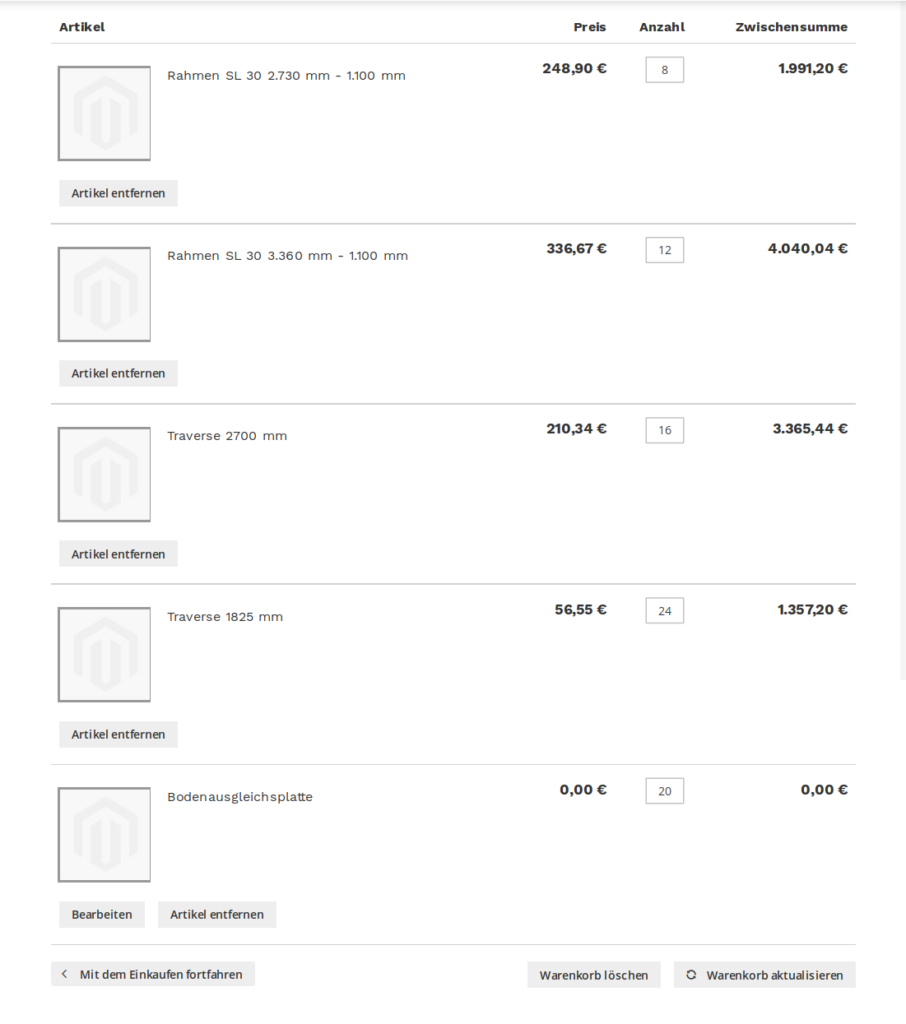
Hotchpotch of simple products in cart
This is why it was necessary to automatically create a bundled product from the parts of the grouped product and set the corresponding options out of the configurator for displaying the completely assembled rack as an entity as soon as the customer adds the rack to cart. A customer that would have configured two different racks would find in his cart only two products that are bundled products on a technical level and contain exactly the parts belonging to the respective rack.
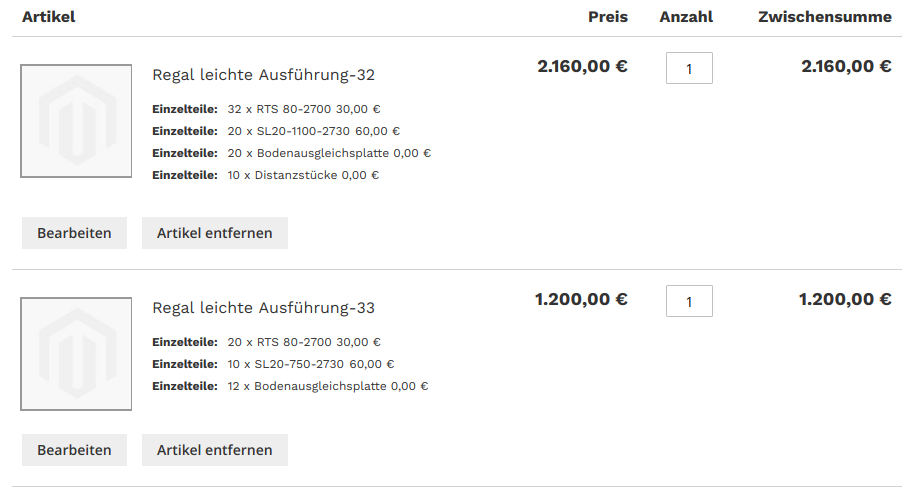
Two pallet racks as bundled products in cart
In the Magento tests there is a php file that creates a bundled product. This file is to be found in
tests/integration/testsuite/Magento/Bundle/_files/product.php.
We used this file as a basis for the creation of a bundled product in our use case.
To transform the grouped product to a bundled product in the right moment (when adding it to cart) it is necessary to edit Magento\Checkout\Model\Cart. The method addProduct($productInfo, $requestInfo = null) has to be extended with this request:
public function addProduct($productInfo, $requestInfo = null)
{
if ($productInfo->getTypeId() === 'grouped') {
$entityId = $this->_createBundleCopy($productInfo, $requestInfo);
$requestInfoNew = $this->_changeRequestInfo
($entityId,$requestInfo);
// ………
First a bundled product with all needed options is being created using the method _createBundleCopy($productInfo, $requestInfo):
protected function _createBundleCopy($productInfo, $requestInfo) {
// Last assigned increment-id
$entityId = intval($this->_helper->getEntityId()) + 1;
// Create options for bundled product
$this->_createOptionsArray($requestInfo);
$productRepository = $this->_objectManager
->create(\Magento\Catalog\Api\ProductRepositoryInterface::class);
$product = $this->_objectManager->create
(\Magento\Catalog\Model\Product::class);
$product->setTypeId('bundle')
->setId($entityId)
->setAttributeSetId(4)
->setWebsiteIds([1])
->setName($productInfo->getName().'-'.$entityId)
->setSku($productInfo->getName().'-'.$entityId)->setVisibility
(\Magento\Catalog\Model\Product\Visibility::VISIBILITY_BOTH)
->setStatus(\Magento\Catalog\Model\Product\Attribute\Source\Status::STATUS_ENABLED)
->setStockData(['use_config_manage_stock' => 1, 'qty' => 1,
'is_qty_decimal' => 0,'is_in_stock' => 1])
->setPriceView(1)
->setPriceType(0)
->setShipmentType(1)
->setPrice(0);
//………
The options for the bundled product are created in _createOptionsArray($requestInfo). For the right mapping to be created it is necessary to get a closer look at the request. A request for a grouped product looks like this:
[uenc] => aHR0cDovL2Fja3J1dGF0LW1pY2hhLnNwbGVuZGlkLWRldi5kZS9yZWdhbC1sZWljaHRlLWF1c2Z1aHJ1bmcuaHRtbA,,
[product] => 29
[selected_configurable_option] =>
[related_product] =>
[form_key] => 0YYmuQDRUOKvb2v4
[super_group] => Array
(
[1] => 10
[2] => 5
[3] => 4
[4] => 0
)
Here the array super_group is in focus because the options for the bundled product need to be created from it. The respective key in the array is the entity ID of the single product. The value is the quantity of the selected product. With these informations the options are created with the method _createOptionsArray($requestInfo). As it is known precisely which simple products were chosen in which quantity by the customer from the configuration of the grouped product the exactly matching options for the bundled product can be created from it.
protected function _createOptionsArray($requestInfo) {
foreach($requestInfo['super_group'] as $key => $value) {
if(intval($value) !== 0) {
$this->_bundleOptionsData[]=
array('title' => 'Name',
'default_title' => 'Name',
'type' => 'select',
'required' => 0,
'delete' => '');
$this->_bundleSelectionsData[] =
array(array('product_id' => $key,
'selection_qty' => $value,
'selection_can_change_qty' => 1,
'delete' => ''));
}
}
}
Now the options can be added to the bundled product. This is done in the second part of the method _createBundleCopy.
protected function _createBundleCopy($productInfo, $requestInfo) {
// ………..
// Add options to bundled product
if (count($this->_bundleOptionsData) > 0) {
$options = [];
foreach ($this->_bundleOptionsData as $key => $optionData) {
if (!(bool)$optionData['delete']) {
$option = $this->_objectManager->create
(\Magento\Bundle\Api\Data\OptionInterfaceFactory::class)
->create(['data' => $optionData]);
$option->setSku($product->getSku());
$option->setOptionId(null);
$links = [];
$bundleLinks = $this->_bundleSelectionsData;
if (!empty($bundleLinks[$key])) {
foreach ($bundleLinks[$key] as $linkData) {
if (!(bool)$linkData['delete']) {
$link = $this->_objectManager->create(\Magento\Bundle\Api\Data\LinkInterfaceFactory::class)
->create(['data' => $linkData]);
$linkProduct = $productRepository->getById($linkData['product_id']);
$link->setSku($linkProduct->getSku());
$link->setQty($linkData['selection_qty']);
if (isset($linkData['selection_can_change_qty'])) {
$link->setCanChangeQuantity($linkData['selection_can_change_qty']);
}
$links[] = $link;
}
}
$option->setProductLinks($links);
$options[] = $option;
}
}
}
$extension = $product->getExtensionAttributes();
$extension->setBundleProductOptions($options);
$product->setExtensionAttributes($extension);
}
$product->save();
return $entityId;
}
After the options are added, the bundled product is saved and will now be available in the web shop.
As a next step the request has to be edited. It has to be transformed from the original request for a grouped product to a request for a bundled product. This requires a closer look at the request for a bundled product:
[uenc] => aHR0cDovL2Fja3J1dGF0LW1pY2hhLnNwbGVuZGlkLWRldi5kZS9idW5kbGV0ZXN0Lmh0bWw,
[product] => 34
[selected_configurable_option] =>
[related_product] =>
[form_key] => 0YYmuQDRUOKvb2v4
[bundle_option] => Array
(
[3] => 15
[4] => 18
)
[qty] => 1
The options for the bundled product can be found in the array [bundle_option]. These have already been created from the array [super_group] by means of the method _createOptionsArray($requestInfo). Now the request is converted so it can be used for a bundled product with the method _changeRequestInfo($entityId, $requestInfo). To do so the options have to be fetched from the database. The options for this bundled product can be found in the table catalog_product_bundle_selection. From the column parent_product_id in this table the entries containing the entity ID of the bundled product have to be selected. As the options have been created just as they are needed for this configuration before, they can now be added to the request:
protected function _changeRequestInfo($entityId, $requestInfo)
{
// Get options for the bundled product from the database
$result = $this->_helper->getBundleOptions($entityId);
foreach($result as $res) {
$option[$res['option_id']] = $res['selection_id'];
}
$requestNew = array();
$requestNew['uenc'] = $requestInfo['uenc'];
// Enter the bundled products entity ID here
$requestNew['product'] = $entityId;
$requestNew['selected_configurable_option'] =
$requestInfo['selected_configurable_option'];
$requestNew['related_product'] = $requestInfo['related_product'];
$requestNew['form_key'] = $requestInfo['form_key'];
$requestNew['bundle_option'] = $option;
$requestNew['qty'] = 1;
return $requestNew;
}
After the request for a grouped product has been transformed into a request for a bundled product the product can now be added to cart as usual. This is done with the method addProduct($productInfo, $requestInfo = null) again:
public function addProduct($productInfo, $requestInfo = null)
{
if ($productInfo->getTypeId() === 'grouped') {
$entityId = $this->_createBundleCopy($productInfo, $requestInfo);
$requestInfoNew = $this->_changeRequestInfo
($entityId, $requestInfo);
$bundleProduct = $this->_helper->getProductById($entityId);
$product = $this->_getProduct($bundleProduct);
$request = $this->_getProductRequest($requestInfoNew);
$productId = $product->getId();
} else
// ……
The further processing is standard Magento.
But there is one thing to note: With this solution a new bundled product will be created from the grouped product in each purchase. We solved that by automatically deleting the respective bundled product whenever a rack has been bought in the web shop.
]]>Together we have organized many events: One conference, four get-together weekends (three in Toulouse and one in Auvergne (somewhere near Le Puy, also known as the Magento Mordor)), we have organized hackathons and shared ideas and code. Most of all, we have spent days and nights not talking about Magento.
While the initial goal of the association was to gather Magento developers and promote the usage of Magento, we now see more and more members criticize it. Magento 2 performance is the best subject you can pick to make everybody troll in the OpenGento Slack. Some members have even completely stopped working with Magento.
We initially all gathered around Magento and we went beyond.
The reality is that we did not gather for Magento. We gathered because of it. We were not trying to improve it, we wanted to improve our experience with it. The fact that you can criticize Magento, the decisions that were made and even decide to stop using it without having to quit the association is for me a great thing.
So why are we still together? What do we talk about ? We talk about Magento. But more in an Alcoholic Anonymous way:
– Hello, my name is Matias and I work with Magento.
– Hello Matias, welcome to OpenGento, the Magento Developers Association!
We talk 90% of the time about Magento, we come to the Slack to complain, share our pain and sometimes we share some good things about it.
For example, during our last hackathons we created a lot of cool things:
We are not Magento fanboys. We will never tell you that dealing with the Magento 2 checkout was the best experience we ever had as a developer, but we will talk frankly about what we like, what we don’t like and why.
More seriously we are a team of passionate developers who sometimes hate Magento but cannot live without it. In the association some have contributed greatly to Magento, do talks to major events and even develop useful projects such as:
We are not a Magento association, we are a Magento developers association. If you think the best for you is to stop using Magento, we will support you. OpenGento is all about love.
And do you want to know the best part? No one ever got banned from OpenGento.
I wish you a Merry Christmas,
Matias, proud member of OpenGento
To become a member: https://opengento.fr/
Twitter: @opengento
 As you probably have already heard, the eol (End of life) for “Magento 1” is set to June 2020. (as announced here: https://magento.com/blog/magento-news/supporting-magento-1-through-june-2020 )
As you probably have already heard, the eol (End of life) for “Magento 1” is set to June 2020. (as announced here: https://magento.com/blog/magento-news/supporting-magento-1-through-june-2020 )
Already some time ago the OpenMage Project was started, to improve the bugfix situation for Magento 1, as even when a fix was already provided, they were often not integrated into official versions even years later. (this changed with Magento 2 a lot to the better)
This was only one of more than 5 forks I counted in the recent years(and there were probably even more). But it is the only one where a community formed around, and which got a wider range of users and contributors.
Lets talk some numbers, by now we are, and we have:
We structured the Project into several phases, oriented on the official Support status of M1.
We are currently in Phase 2.
When there was no official EOL set.
Keep a maximum on Backwards Compatibility to the official Release, to make it possible to switch without losing any features. Also no new Features.
We Focused on Bug and Performance fixes.
An EOL was set, and is slowly approaching.
We start to accept minor Backwards Compatibility breaks. Cleaning up the code from Parts which are not recommended to use anymore as they are outdated or even harmful.
Examples are the removal of the View Logging (this thing, which writes on every pageview to the database, and is for nearly all cases better replaced by Google Analytics), and the removal of the Compiler Feature (which in Magento1 is not needed anymore, since PHP brings its own OpCache)
Archiving a proper Continuous Integration Environment to archive enough stability to beeing able for bigger internal changes (we have some performance improvements in the pipeline for eav related database queries and the Index Process in general)
Also in this phase we will set up a proper Release Schedule. The current Plan is to have a stable Major release each January, which includes new Features and possible Backwards Compatibility breaks. Maybe one bugfix release per month. We will probably establish an LTS release every 2 or 4 years depending on what the users have more interest in. First LTS release is the current Magento 1 release, which we will continue to provide with bug fixes for at least 2 LTS releases and then decide depending on where we have how many users.
That said, we will work together with existing extension vendors to make sure a later major release of OpenMage will not cause major breaks
When we reach this phase, all our processes are stable enough to approach actual Feature development.
Some of this may involve a lighter default theme, which is less javascript heavy, performs better in the google pagespeed insights and more mobile friendly.
Also an auto updater like established with WordPress may be possible, to improve the situation for the Shops which do prefer to self host and try to keep the maintenance cost low.
While we have through the community contact to some of the security researchers, this only helps to fix Issues, which got already found. We will also keep contact to hosting companies, which are good in tracking security issues which are already used in the wild.
But the best way to find security issues has proven to be bug bounties. As this requires a certain amount of money flow, the OpenMage Project will not be able to provide this part.
Luckily there are some people who took this part over and build a company around this security Topic. You can find and follow them at https://mage-one.com/
The missed point here is, that Magento 2 did up its game by several levels, and with doing this, also their target audience. Magento 1 is able to perform quite well, and also the development speed is better than with Magento 2. But it does not scale well. Magento 2 is designed for way bigger Merchants and Projects, and to scale even further to match future needs which will come.
Therefore the overlap in potential target audience got quite small.
Magento2 is now suitable for big projects, which could never run on Magento 1, or only with very big adjustments. Therefore Magento 2 is no longer suitable for many small merchants or for self hosting. With Magento 1 a merchant was able to install it on a webspace without needing a developer. Magento 2 is even for a single developer sometimes hard to install properly.
OpenMage does not compete with Magento 2.
OpenMage is competing with solutions like Shopware, Sylius and Shopify.
OpenMage is for Companies, which for diverse reasons would not switch to Magento 2 anyway, but would consider to switch to one of the other Platforms. For them, OpenMage is the more cost efficient solution, as it only leads to the price of an update, not a replatforming.
]]>We started as probably many of you also did: with Magento and some additional extensions to add missing features and bring value to the customer. Over time it became more and more and luckily the business flourishing. By this we encountered areas in which Magento is well known: performance and easy scalability. Much was done but in the end the easiest solution disguise was chosen: Full Page Caching.
Suddenly everything seemed fine again. At least until someone had the brilliant idea of showing “more accurate/real time data” to customers. We started with a simple thing: real delivery time/availability information on product detail pages. Everything was implemented, tested and approved but after deployment nothing changed. Everybody forgot our full page cache.
As we do not use a fpc solution that supports ESI blocks we tried the standard way of making AJAX requests for the stuff we wanted updating and it worked. Yay!! Soon after adding the availability information to the detail pages we added those to product listings, and hell broke loose. With 30 products per page we suddenly created 30 Ajax requests, all to a Magento controller. After a bit of research we found that we tried to access the user session concurrently and there is a slight problem with PHP-session locking for this which caused 15-30% of our AJAX requests to result in “503 Service not available”.
Somehow we were not able to implement this in the preDispatch() method as it should normally work:
public function preDispatch()
{
$this->getLayout()->setArea($this->_currentArea);
$this->setFlag('', self::FLAG_NO_START_SESSION, 1); // Should skip session startup
$this->setFlag('', self::FLAG_NO_PRE_DISPATCH, 1);
$this->setFlag('', self::FLAG_NO_POST_DISPATCH, 1);
parent::preDispatch();
return $this;
}
As we could not figure out how to bypass this we needed to come up with another idea and we agreed upon writing our own product-availability-service.
We agreed on building this one in node.js. Partially because we wanted hands on experiences in an area that was new to most of us and partially because we thought it would be a good fit for the needed features. For fast implementation and also to prevent us from reinventing everything we use express.js
Using express.js for this is dead simple. After installing express-generator and mysql for npm for database connection you can simply generate the “project” by
$ express-generate advent
This will result in a base project structure that can be used for our small example. Additionally we need to install the mysql stuff for npm:
$ npm install mysql --save
and set it up afterwards in models/db.js
var mysql = require('mysql');
//local mysql db connection depending on your sql-setup
var connection = mysql.createConnection({
host : 'localhost',
port: '3307',
user : 'adv',
password : 'testen123',
database : 'advent'
});
connection.connect(function(err) {
if (err) throw err;
});
Now we can prepare the real controller for request handling. I put it in routes/stockstatus.js
var express = require('express');
var router = express.Router();
var db = require('../models/db.js');
/* GET stock for product. */
router.get('/:itemid', function(req, res, next) {
var itemid = req.params.itemid;
var results = db.query('SELECT qty from stock where id = ?', [itemid], function (error, results, fields) {
if(error){
res.send(JSON.stringify({"status": 500, "error": error, "response": null}));
} else {
res.send(JSON.stringify({"status": 200, "error": null, "response": results}));
}
});
});
module.exports = router;
Last thing we need is to tell our app how to access this endpoint. This will go to app.js where we need to add
var stockstatusRouter = require('./routes/stockstatus');
app.use('/stockstatus/', stockstatusRouter);
For this example I used a very simplistic table with just a tiny bit of sample data:
CREATE TABLE stock (`id` INT(11) NOT NULL, `qty` INT(11) NOT NULL DEFAULT 0); ALTER TABLE stock ADD PRIMARY KEY (id); ALTER TABLE stock MODIFY id INT(11) NOT NULL AUTO_INCREMENT; INSERT INTO stock (qty) VALUES (4),(5),(0),(10);
This is all you need to run the application with
$ npm start
Normally you can access it now under http://localhost:3000/stockstatus/2 to get a JSON response.
Conclusion
As you can see it is really super simple to split off some functionalities or add new by adding a very small node.js app. Personally i would advice against enlarging those APIs without boundaries, instead I would suggest having specialized services for every need you have as in: “Do one thing, but do it right”. Those are easier to adapt, replace and scale if need be.
Really nobody likes this Angular vs React stuff, every solution has it’s pros and cons. The essential question is would you choose Angular because you know React is not the right tool in this case for your customer? Sometimes this also means to send this customer away. But when is React the right tool and when is Angular the right tool? So I´d like to do is not present you a typical Angular vs. React comparison.
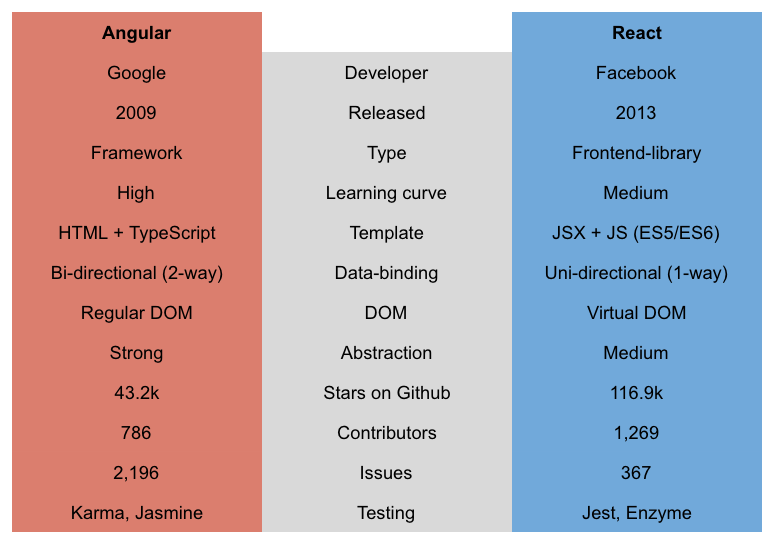
After reading these key facts you might think React is heaps better because it has more stars, more contributors and fewer issues. But the big difference is the application type and React is still a frontend-library. So if you want to reach the same features with React that Angular brings out of the box you need a lot of components. To give you an impression about how many, you can check this React awesome list. So to update the key-comparison facts table above you need to add the issues and starts of the React components that are provided by Angular out of the box.
So what have we learned already? React is more lightweight then Angular. React gives the developer more flexibility. But with big flexibility there comes the big chance to build legacy code that nobody understands afterwards. It depends on the experience of the developer team you have or hire to build your new shiny Venia frontend.
I often asked myself why Magento choose React as the base for their Venia theme? Sometimes when I’m in a bad mood I hear a voice that is saying: “They liked to mix HTML and PHP and now they like to mix HTML and JS.” and when I’m in a good mood I hear the same voice telling me: “There are more React developers out there, also Magento need a lightweight frontend and not a complete framework.”. You see it depends 
So when would I suggest to choose Angular instead of React for your customer? First and the most important thing: You need skillful and experienced javascript developers that like to build a storefront from the ground up and they are not shy to throw things away or rebuild complete components. Secondly, you need a big customer with a vision, time and, of cource, money. Thirdly, you need an idea how to build up a flexible headless infrastructure. Fourthly, the storefront you will build will solve a lot of pain points for the customer and will bring shiny new features to the buyers of your customer like easily personalized category pages, homepages, offline shopping and so on.
Would I suggest somebody to use the Venia theme at the moment (this is written in December 2018)? Yes, if you have really good javascript developer team and they want to build a lot of features from the ground up. If you are a small- or middle-sized customer I would not suggest using the Venia theme to you. If you want to know what kind of features are already in the Venia theme you can check the roadmap (at the moment we are in phase 2). You see a lot of important features will be ready in the future. Maybe you should check if DEITY Falcon or Vue Storefront has all the features you need.
I already wrote a blog post about PWA for small- and middle-sized customer (in german). Additional hint: Please do not think that PWA === Headless this is just not true. It is possible to use a lot of features without the need for a headless application. But normally when you do a complete new frontend then you also want to have the headless and offline shopping stuff.
If you want to use Angular as a headless frontend, Magento2 for the backend, Lizards and Pumpkins as a middleware, ElasticSearch for search, payment provider like Klarna or Payone or Paypal and you want an enterprise solution that is unit-tested then you have to ask Flagbit about their solution. In 2019 we will give back our angular storefront and our base components to the community (open source).
At the end I will leave you with a Quote from Andrei Neagoie from 8. November 2018
Angular is the entire kitchen that gives you all the tools necessary for you to build the meal that is your web app . If I am a bank with lots of developers, I like Angular to keep everyone working in the same pattern.
React is the oven. You most likely will need more tools to bake that cake, but it allows you the flexibility to pick and choose what tools you want based on your needs. If I’m a tech company with strong senior developers that can make good decisions, I like React.js.
Vue is the microwave that allows you to get up and running really fast and make your cooking life efficient and easy. If I am a startup with a young developer team and a strict deadline, I like Vue.js.
Resource List
]]>Magento 2 has a lot of awesome new approaches to day-to-day issues, but also suites the classical Magento mantra “Let’s make standards the Magento Way ”
”
If you give it a chance and find your way around the quirks of it, it’s not so difficult at all.
Magento 2 switched to very common standard components, which a lot of you already know: jQuery, requireJS, knockout.js – Some are not so common: Less
But unfortunately they still follow their Mantra to implement these standards in a slightly Magento’ish way. On one hand I can absolutely understand their reasons to do so, on the other hand: it makes it much more difficult to get started with Magento2.
Yes: the bigger part of web-development-land uses scss. But to be honest: Less isn’t that different at all. Slight syntax differences but the concepts are identical.
Well, when this part of Magento 2 was built, there was no stable and maintained PHP-based scss parser. So they used Less for Magento 2.
Real Less, that you can directly parse with a native less compiler? Modularity doesn’t go well hand-in-hand with plain Less files. You can’t tell the processor, to include files from different directories based on patterns.
You only have two options now:
I would have created something similar to Magento’s //@magento_import ‘hack’. Once you understand that concept it’s not just easy but also very flexible and saves resources if specific modules are turned off.
If you work with Magento’s native PHP-based Less workflow it’s very frustrating. Whenever you change a source file in your theme, you have to delete at least 3 different files in at least 2 different directories. There’s no built-in automation for that (var/view_preprocessed and pub/static)
If you complain about that at Magento, they gonne reply that no one is using that. That’s not quite true, I would say, but what’s the preferred way then? Well … just use a local task runner like Grunt that does it for you. Magento 2 already ships default config files for nodeJS and grunt so you can start right away and take advantage of the file watcher benefit — change your less file, get rebuilt css filesautomatically.
Using that adds additional technology layers on top of your already quite high technology stack (hmtl, css, less, php, mysql, javascript + nodejs, grunt)
Yeah … okay … that one particulary is a pain in the ass. It’s a freaking mashup of random configurating XML, knockout.js with html templates, requireJS and jQuery Widgets … It takes a good while to understand it, if you really accomplish the “understanding”.
Magento thought about a way to load data asynchronously together with reusable generic elements in the backend and frontend. In order to not rewrite every component, there had to be a way to configure each component individually. That’s usually done with json injected into the component.
But Magento wouldn’t be Magento if they’re not using ..xxXML for it! With Magento 2’s new layout xml capabilities you can create hierarchical structures containing arrays and data (like objects i.e.). So you can also create the configuration for UI components via layout XML …
That might look like some arbitrary XML that doesn’t follow any rules. Which … more or less …is exactly that: arbitrary XML  but it’s flexible and interchangeable!
but it’s flexible and interchangeable!
If you want to get a better understanding of UI components, I can highly recommend Alan Storm’s Series about UI components in Magento 2.
That’s one of the smaller parts of Magento 2 where no tool can help you and where no palliation is available.
But there are other crucial parts, where someone is to our rescue …
Magento’s Caching now supports a full page cache as well as a wide variety of other cache types. If you’re writing an extension that touches different parts of the app you gotta clean the caches A LOT … So the easiest workaround here would be: disable the caches. Haha … yeah … it doesn’t work that way.
If you disable the caches Magento becomes ridiculously slow on every request. Manually partial cache cleaning instead is a pain in the but again, because you always have to think about which caches you have to clear. And if config is one of them — get yourself a coffee  because you can’t kick out just the affected cache fragments but have to clear the full cache section.
because you can’t kick out just the affected cache fragments but have to clear the full cache section.
Make sure you’re using redis to have a faster cache backend; that doesn’t solve the problem, but at least makes everything a tiny bit faster.
The only thing that might help you here is a nice nodeJS based tool, developed by mage2tv’s Vinai Kopp, named cache-clean.js. Running as a watcher, it’ll clean just these fragements/cache types that are affected by your file changes. In that case you can have all caches enabled but still work with 95% of the full cached performance!
There’s a very quick but yet effective tutorial on how to set it up with PHPStorm, written bei Timon de Groot.
Functional extensibility is always a tricky topic and not easy to handle. Most application chose to go along with publish/subscribe implementations. You can still create subscribers (called Observers) in Magento 2, but there’s a more powerful way: Plugins!
Magento 2 generates a lot of PHP classes automatically based on configuration options and source code. By simply creating 3 lines of XML together with a new class, you can hook into almost every public method call. That’s done by parsing your new class and look for method names of the original class, prefixed by either around, before or after. Magento will then magically create a new class (called Interceptors) that (i.e. before) first calls your method and after its execution calls the original method.
And the cool thing here is: you can have as much plugins chained in a specific order as you like. Even around, before or after. Magento takes care of it.
It is! But in developer mode … oh hell … Magento will create those intercepting classes all the time for all the methods, no matter if you need them or not as long as there’s a plugin configured. And I dare you to go for it with xDebug … The stack traces are toilet paper long!
If you don’t care about these repetitive debug cycles with “autogenic training” like immersion … you’re fine! One note: Only use around Plugins if it’s unavoidable. Their impact in performance is much worse than before and after.
Magento 2 is more difficult than Magento 1, especially looking into frontend development. As always: the wonderful Magento community takes care of some of Magento’s ceveats and try to help with their expertise. Be it with tutorials or tools. Once you understand the ups and downs of Magento 2, how you probably did with Magento 1 years ago, you might have some real fun and some very tragic moments with it!
Magento’s Developer Documentation is a very good way to start diving into Magento.
]]>Software is not reliable.
Now, by and large the services that we use every day are extremely reliable. To my memory Google Search has essentially never been “down”, and when Facebook went down it was national news.
Each of these services still experience regular failures. The hardware our software runs on is imperfect, let alone the software itself. Networking is subject to so many random events it can sometimes fail for essentially no reason at all.
It is in the nature of software to fail. However, it is never comfortable when it does. Failing software can quickly cause a significant dent in company earnings. It has become such a ubiquitous, integral part of our businesses that whenever software does fail it ends up costing someone money.
So, we have software that is essentially doomed to fail coupled with an environment in which software amounts to critical infrastructure. We thus need to become extremely good at understanding software failures:
The process of analysing a failure is called a “post mortem”, “retrospective”, “after action report”, “failure analysis” or a host of other names. We’ll stick to “post mortem” for this post as it’s perhaps the most common.
To understand why software fails, it’s perhaps first stepping back and examining what we mean by “software”.
A software service provides some functionality to its users that allow its users to do something valuable. For example, a word processor may help users form, view, render and print a document. Or a website might allow the purchase of a nice shirt.
Each of these components of software is essentially unimaginably complex.
Consider a classic eCommerce service. It looks something like:
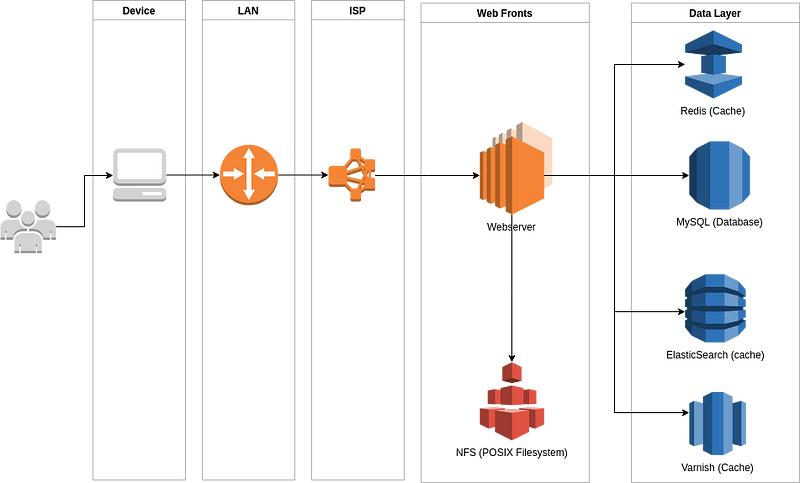
There are a multitude of devices that connect us to our favourite services. We can see a list of the computers that we pass through to visit our services by running the traceroute command:
$ traceroute google.com
Which shows that it takes ~7 network hops to get to Google:
traceroute to google.com (216.58.205.238), 30 hops max, 60 byte packets 1 _gateway (10.0.0.1) 1.497 ms 1.547 ms 1.596 ms 2 fra1813aihr001.versatel.de (62.214.63.98) 12.248 ms 13.251 ms 13.415 ms 3 62.214.36.217 (62.214.36.217) 12.279 ms 13.632 ms 13.122 ms 4 62.214.37.130 (62.214.37.130) 14.006 ms 62.214.37.134 (62.214.37.134) 13.643 ms 62.214.37.130 (62.214.37.130) 13.932 ms 5 * * * 6 * * * 7 216.239.40.58 (216.239.40.58) 16.410 ms 216.239.47.246 (216.239.47.246) 16.535 ms 216.239.56.148 (216.239.56.148) 16.612 ms 8 108.170.251.208 (108.170.251.208) 28.427 ms 216.239.48.45 (216.239.48.45) 16.370 ms 216.239.48.43 (216.239.48.43) 16.366 ms 9 fra15s24-in-f238.1e100.net (216.58.205.238) 16.335 ms 209.85.245.30 (209.85.245.30) 16.337 ms fra15s24-in-f14.1e100.net (216.58.205.238) 16.310 ms
In the image above, that means getting as far as the “web fronts” — not even the full way through the application. Additionally, each component of this setup, from the phones used to connect to the databases is itself a complex implementation:
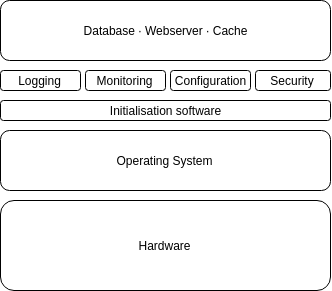
All this amounts to a level of complexity that is essentially impossible to reason about any given point in time, and all of which is guaranteed to fail at some point.
The aforementioned systems are complex but manageable through the disciplined use of abstraction layers to “contain” each individual unit of complexity in reasonable ways. For example, we don’t usually consider the browser that we’re visiting the website with — just the website itself.
However, software is not developed in a vacuum — it’s developed to serve a very human purpose. Humans do not come without their own ways of reasoning about the world; they model it in terms of budgets, timelines, stakeholders, return on investment as well as various other topics.
Software exists as part of the human ecosystem. Consider the stakeholders of the aforementioned eCommerce project:
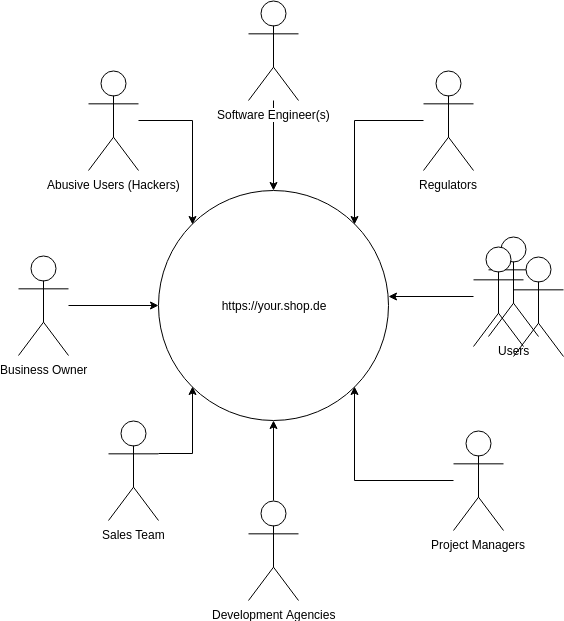
Each of those stakeholders has a slightly different model for how the service works and different designs on how it should work. For example:
Each of these people attempt to influence the direction of a project in a way that furthers their own goals, as best as possible. Unfortunately it’s not always the case that these goals are compatible with each other. For example, the business owner might want to ship a new feature quickly, but the software engineer cannot do it without introducing risk into the application. The sales team might want to sell merchandising positions on the website, but the users trust the site to be objective. The project manager wants to deliver their features by the appropriate quarter, but the developers want to pay down debt introduced by the last set of features.
All of these pressures make for an incredibly complex system to express as software.
Given that we’ve established the nature of our complex system and the stakeholders that are involved it’s difficult to determine who has responsibility for the entire system. Arguments could be made for all stakeholders:
However, to allocate responsibility in such a shallow way does a disservice to that stakeholder, and to the project in general.
Each stakeholder makes decisions that they feel will establish the best possible outcome for the system in general, or at worst best for themselves. They make these decisions due to the unique constraints they face, and the conceptual model of the system that they have.
Accordingly, each failure is at least partially defensible and each success at least partially due to luck. It is only by examining the system as a whole and the interactions between each component and each stakeholder that the failure may be understood.
Allocating responsibility (and thus blame) for a system in its entirety to a single stakeholder is ludacris.
Any system of sufficient complexity is in a constant state of partial failure (degradation). Generally speaking, in both the human and technical expression of the system there’s a level of “tolerated failure”. This might include things like:
However, occasionally multiple failure chain together and create some sort of catastrophe or “incident”. These failures almost never have a singular, root cause but are rather as a result of conflicting pressures or discrepancies in the models of software.
The process of responding to these catastrophes is called “incident response”.
The process of incident response is a topic that is well worth researching further into and has been covered in other posts but has bearing on writing an effective post mortem.
Broadly, incident response is a specific process that’s designed to escalate the understanding, recovery and analysis of a failure to the highest priority among all stakeholders. At Sitewards, it begins with the phrase:
“I hereby declare this an incident”
Following which there is a specific procedure that must be followed that handles resolving the issue.
One of the things that the incident response process does is established a communication medium that is used only for the purpose of resolving the incident. Chat tools such as Slack do a particularly good job of this; opening a channel called “#incident — 2018–12–20 — database-failure” and inviting members to it allows centralised communication and a written log of all that happens during an incident.
It is extremely important that all communication happens via this chat channel, and if there are out of chat communications of any kind (such as in meatspace or via telco) those communications are immediately summarised in the chat channel in detail and with justifications.
Specifically within the chat one should:
This information will be incredibly useful when later recreating the event for understanding while writing the post mortem.
So far we’ve established both that our software systems are complex, complex systems are destined to fail and when they do fail they cost us many hours of useful work. We’ve further created a process that allows us to quickly fix these issues in a temporary way as they arise, but we need to go further and establish how the issue came to be and what we can do to prevent it in future.
That process is the “post mortem”.
The nature of complex system failure is that they tacitly encourage a naive explanation of the issue. Any system of sufficient complexity relies on nested abstractions to reason about its behavior and its trivial to fall back on these abstractions having resolved an issue, rather than attempting to pick at whether these abstractions are correct.
Consider the failure of:
This is a super simple error that sits within the abstraction of “database machine thing”. It can be easily fixed by increasing disk size, or deleting stale content.
Once the issue is fixed it is tempting to simply mark that particular situation as anomalous and return to work, never picking at the complexity that generated this particular problem.
Accordingly, it’s important that the post mortem process must be sacred, and endorsed by those who allocate workload (management). Unless it is understood encouraged within the organisation there will be no analysis into these issues and they (or similar) will remain, eating into team productivity and increasing business risk.
The human memory is famously flawed, and one of the crueler aspects of understanding failure is the nature of failure introduces stress, and stress prevents us from remembering and thus understanding the failure.
When we’ve discovered and resolved critical failures, given each other a high-five and send those elated emails off to stakeholders that “the problem is fixed now” we’ve already forgotten the vast majority of what happened during the incident.
Accordingly, the first step of the post mortem process is to re-read and summarise what happened at each stage in the post mortem. It’s important to get as much detail as possible for each event within the post mortem, as it will be later used to identify contributing causes.
Given the truth that failures will happen, it must also become evident that not all failures are equal. A failure of a non-essential service may annoy several users, but a failure of user management service or a security breach will upset all customers instantly.
In order to determine the level of invest in making sure this issue doesn’t arise it needs to be understood the impacts of this issue. That allows stakeholders who manage budget to allocate some budget to either resolving the issue, or simply accepting the risk.
It’s useful to list impacts to stakeholders separately, such as:
It’s additionally useful to be specific about the financial result of those impacts, such as:
Now that we’ve got a canonical, detailed record of the issue we can start to establish each of the things that:
Contributing factors can be any number of different issues, from the technical:
To the human:
rm -rf . /* “Or the economic:
Or the abstract:
Each of these issues is fine, and even when they’re assigned to a particular person or team (such as “project management”) it is unreasonable to allocate some fault at that time.
Instead, the issues require a recursive understanding. The common ways of doing this are:
Such recursive enquiry provides much more insight into each given issue, and can highlight systemic issues within the system that may cause other issues in future. Consider “The disk was full on db01”. This might go through the following steps:
We can see the many factors that gave rise to the fact db01 failed. It was not a singular failure but rather a whole set of process violations that led to this failure.
Lastly, it is sometimes helpful to identity particular markers where complex systems have been known to fail previously. This includes things like:
As mentioned, complex systems are always in a state of failure. This failure happened now, uniquely, which indicates a series of things happened at this point. But the system copes with this, and perhaps other failures on a regular basis that are similar to this disaster. The mitigating factors of this disaster should be identified as a mechanism to understand how existing prevents are already working, and where to allocate time to continue those. Questions such as:
The recursive approach applied to the contributing factors works equally well here.
Finally, once the contributing and mitigating factors have been identified they need to be expressed as work items (tickets or similar) that can be consumed in a predictable way as part of a normal work routine.
These work items are the true value of the post mortem and the post mortem has no value until it causes some change in either the understanding or the process of system development.
Lastly, given the complex and thorough nature of these failures not all stakeholders can afford to dive deeply into the issue. However, to maintain some sense of predictability within the business stakeholder (especially at a C level) need some understanding that the issue is understood, and that changes have been made to mitigate this risk going forward.
An abstract that summarises the issue, impact, contributing and mitigating factors and actionable items in ~300 words provides some level of understanding without delving into the complexity.
Lastly, a post mortem that is not read is of no use. Accordingly once a post mortem has been written it must be followed up until all tasks it outlines have either been completed or marked as “wontfix”.
To this end, immediately upon conclusion of incident response a recurring meeting to discuss the post mortem is created 30 days in the future, repeating monthly. In this meeting all those stakeholders revisit the post mortem, and check whether the work required to prevent this risk in future has been completed in some capacity. If the work has not been completed, the future meeting remains scheduled and the meeting repeats.
Once the post mortem is closed, all future follow up meetings for this post mortem are cancelled. The incident should then go out and celebrate; perhaps go and get a meal, or a coffee.
Lastly, once completed post mortems should be shared at an all hands meeting as a cause for celebration.
We operate extremely complex software systems in our daily lives, made more complex by the human systems that overlay them. Complex systems are inherently failure prone and that failure can be extraordinarily expensive. Having an incident response process and being disciplined in documenting the results of the incident during this process can help us understand the failure in a much greater depth than otherwise possible. We can do an analysis of these detailed records to identify causal and mitigating factors and make changes to our system such that we reduce the risk of such issues happening again. Follow up meetings provide accountability and ensure that the time spent writing the post mortem goes unwasted.