Being a software developer drives one fundamental lesson into you:
Software is not reliable.
Now, by and large the services that we use every day are extremely reliable. To my memory Google Search has essentially never been “down”, and when Facebook went down it was national news.
Each of these services still experience regular failures. The hardware our software runs on is imperfect, let alone the software itself. Networking is subject to so many random events it can sometimes fail for essentially no reason at all.
It is in the nature of software to fail. However, it is never comfortable when it does. Failing software can quickly cause a significant dent in company earnings. It has become such a ubiquitous, integral part of our businesses that whenever software does fail it ends up costing someone money.
So, we have software that is essentially doomed to fail coupled with an environment in which software amounts to critical infrastructure. We thus need to become extremely good at understanding software failures:
- How they can be prevented
- How the impact of an issue can be limited
- How we can quickly recover from an issue
The process of analysing a failure is called a “post mortem”, “retrospective”, “after action report”, “failure analysis” or a host of other names. We’ll stick to “post mortem” for this post as it’s perhaps the most common.
Complex Systems
To understand why software fails, it’s perhaps first stepping back and examining what we mean by “software”.
A software service provides some functionality to its users that allow its users to do something valuable. For example, a word processor may help users form, view, render and print a document. Or a website might allow the purchase of a nice shirt.
Each of these components of software is essentially unimaginably complex.
Technical Complexity
Consider a classic eCommerce service. It looks something like:
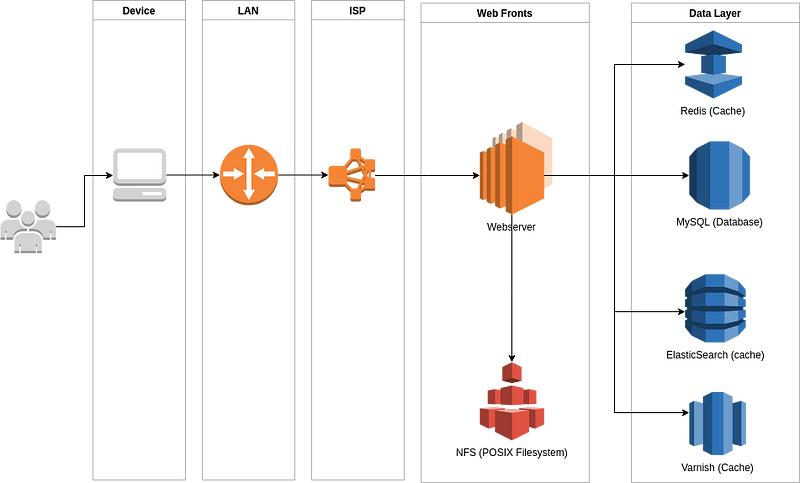
There are a multitude of devices that connect us to our favourite services. We can see a list of the computers that we pass through to visit our services by running the traceroute command:
$ traceroute google.com
Which shows that it takes ~7 network hops to get to Google:
traceroute to google.com (216.58.205.238), 30 hops max, 60 byte packets 1 _gateway (10.0.0.1) 1.497 ms 1.547 ms 1.596 ms 2 fra1813aihr001.versatel.de (62.214.63.98) 12.248 ms 13.251 ms 13.415 ms 3 62.214.36.217 (62.214.36.217) 12.279 ms 13.632 ms 13.122 ms 4 62.214.37.130 (62.214.37.130) 14.006 ms 62.214.37.134 (62.214.37.134) 13.643 ms 62.214.37.130 (62.214.37.130) 13.932 ms 5 * * * 6 * * * 7 216.239.40.58 (216.239.40.58) 16.410 ms 216.239.47.246 (216.239.47.246) 16.535 ms 216.239.56.148 (216.239.56.148) 16.612 ms 8 108.170.251.208 (108.170.251.208) 28.427 ms 216.239.48.45 (216.239.48.45) 16.370 ms 216.239.48.43 (216.239.48.43) 16.366 ms 9 fra15s24-in-f238.1e100.net (216.58.205.238) 16.335 ms 209.85.245.30 (209.85.245.30) 16.337 ms fra15s24-in-f14.1e100.net (216.58.205.238) 16.310 ms
In the image above, that means getting as far as the “web fronts” — not even the full way through the application. Additionally, each component of this setup, from the phones used to connect to the databases is itself a complex implementation:
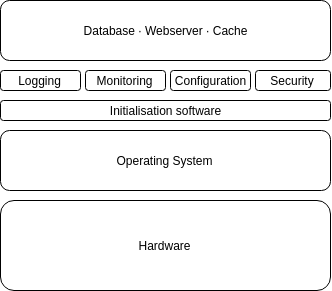
All this amounts to a level of complexity that is essentially impossible to reason about any given point in time, and all of which is guaranteed to fail at some point.
Human Complexity
The aforementioned systems are complex but manageable through the disciplined use of abstraction layers to “contain” each individual unit of complexity in reasonable ways. For example, we don’t usually consider the browser that we’re visiting the website with — just the website itself.
However, software is not developed in a vacuum — it’s developed to serve a very human purpose. Humans do not come without their own ways of reasoning about the world; they model it in terms of budgets, timelines, stakeholders, return on investment as well as various other topics.
Software exists as part of the human ecosystem. Consider the stakeholders of the aforementioned eCommerce project:
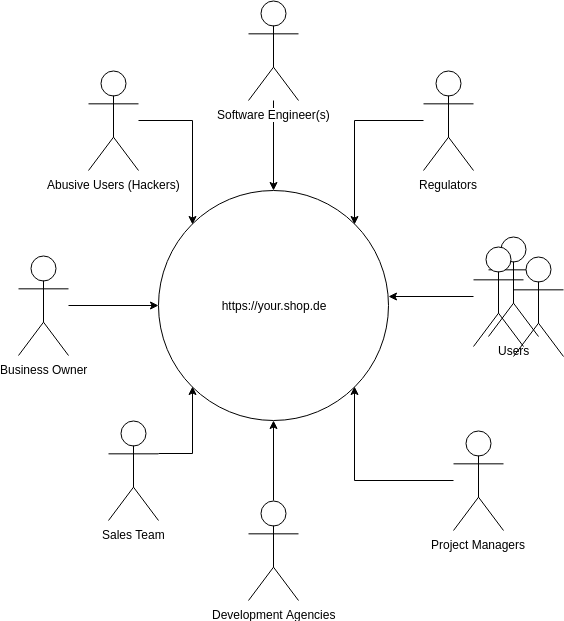
Each of those stakeholders has a slightly different model for how the service works and different designs on how it should work. For example:
- Users want to continue to derive value from the service
- Business Owner wants a return on investment to maintain a profitable business
- Software Engineer wants to keep the software reasonable and up to date to maintain development velocity and mitigate risk
- Project manager wants to deliver the project in a predictable way to the business owner
- Sales team want to be able to leverage their website to increase their sales
- Regulators want to ensure the data is compliant with the law
- Hackers want to monetize the site for their own purposes
Each of these people attempt to influence the direction of a project in a way that furthers their own goals, as best as possible. Unfortunately it’s not always the case that these goals are compatible with each other. For example, the business owner might want to ship a new feature quickly, but the software engineer cannot do it without introducing risk into the application. The sales team might want to sell merchandising positions on the website, but the users trust the site to be objective. The project manager wants to deliver their features by the appropriate quarter, but the developers want to pay down debt introduced by the last set of features.
All of these pressures make for an incredibly complex system to express as software.
Allocating responsibility in a complex system
Given that we’ve established the nature of our complex system and the stakeholders that are involved it’s difficult to determine who has responsibility for the entire system. Arguments could be made for all stakeholders:
- The business owner might be responsible for ensuring all other stakeholders make appropriate tradeoffs
- The developer might be responsible for the safety and security of the system
- The hacker might be responsible for not abusing the system
- The users might be responsible for understanding the risks of the system they’re using
However, to allocate responsibility in such a shallow way does a disservice to that stakeholder, and to the project in general.
Each stakeholder makes decisions that they feel will establish the best possible outcome for the system in general, or at worst best for themselves. They make these decisions due to the unique constraints they face, and the conceptual model of the system that they have.
Accordingly, each failure is at least partially defensible and each success at least partially due to luck. It is only by examining the system as a whole and the interactions between each component and each stakeholder that the failure may be understood.
Allocating responsibility (and thus blame) for a system in its entirety to a single stakeholder is ludacris.
The nature of failure in complex systems
Any system of sufficient complexity is in a constant state of partial failure (degradation). Generally speaking, in both the human and technical expression of the system there’s a level of “tolerated failure”. This might include things like:
- Technical: A single replica in a multi-node web service stops responding properly and needs to be restarted
- Technical: Network congestion at an intermediary increases ~5% of application response times
- Technical: In periods of high traffic, the database might reject connections it knows it cannot tolerate, leading to user errors
- Human: The business owner may choose to take on technical debt to push a feature quickly to market
- Human: A developer may choose to build in addressing technical debt in feature work
However, occasionally multiple failure chain together and create some sort of catastrophe or “incident”. These failures almost never have a singular, root cause but are rather as a result of conflicting pressures or discrepancies in the models of software.
The process of responding to these catastrophes is called “incident response”.
Incident response
The process of incident response is a topic that is well worth researching further into and has been covered in other posts but has bearing on writing an effective post mortem.
Broadly, incident response is a specific process that’s designed to escalate the understanding, recovery and analysis of a failure to the highest priority among all stakeholders. At Sitewards, it begins with the phrase:
“I hereby declare this an incident”
Following which there is a specific procedure that must be followed that handles resolving the issue.
Document Everything
One of the things that the incident response process does is established a communication medium that is used only for the purpose of resolving the incident. Chat tools such as Slack do a particularly good job of this; opening a channel called “#incident — 2018–12–20 — database-failure” and inviting members to it allows centralised communication and a written log of all that happens during an incident.
It is extremely important that all communication happens via this chat channel, and if there are out of chat communications of any kind (such as in meatspace or via telco) those communications are immediately summarised in the chat channel in detail and with justifications.
Specifically within the chat one should:
- Assign roles
- Establish a shared understanding of the issue, complete with links to graphs, alerts or screenshots that demonstrate the issue
- Handle questions from all team members involved in
- Document or attach any information that helps diagnose issues. Graphs, alerts, traces or whatever
- Document solutions tried (and failed)
- Document where documentation was confusing or unhelpful
This information will be incredibly useful when later recreating the event for understanding while writing the post mortem.
Post Mortems
So far we’ve established both that our software systems are complex, complex systems are destined to fail and when they do fail they cost us many hours of useful work. We’ve further created a process that allows us to quickly fix these issues in a temporary way as they arise, but we need to go further and establish how the issue came to be and what we can do to prevent it in future.
That process is the “post mortem”.
Allocate budget
The nature of complex system failure is that they tacitly encourage a naive explanation of the issue. Any system of sufficient complexity relies on nested abstractions to reason about its behavior and its trivial to fall back on these abstractions having resolved an issue, rather than attempting to pick at whether these abstractions are correct.
Consider the failure of:
- The disk was full on db01
This is a super simple error that sits within the abstraction of “database machine thing”. It can be easily fixed by increasing disk size, or deleting stale content.
Once the issue is fixed it is tempting to simply mark that particular situation as anomalous and return to work, never picking at the complexity that generated this particular problem.
Accordingly, it’s important that the post mortem process must be sacred, and endorsed by those who allocate workload (management). Unless it is understood encouraged within the organisation there will be no analysis into these issues and they (or similar) will remain, eating into team productivity and increasing business risk.
Establishing a shared understanding of the issue
The human memory is famously flawed, and one of the crueler aspects of understanding failure is the nature of failure introduces stress, and stress prevents us from remembering and thus understanding the failure.
When we’ve discovered and resolved critical failures, given each other a high-five and send those elated emails off to stakeholders that “the problem is fixed now” we’ve already forgotten the vast majority of what happened during the incident.
Accordingly, the first step of the post mortem process is to re-read and summarise what happened at each stage in the post mortem. It’s important to get as much detail as possible for each event within the post mortem, as it will be later used to identify contributing causes.
Establish a shared understanding of impact
Given the truth that failures will happen, it must also become evident that not all failures are equal. A failure of a non-essential service may annoy several users, but a failure of user management service or a security breach will upset all customers instantly.
In order to determine the level of invest in making sure this issue doesn’t arise it needs to be understood the impacts of this issue. That allows stakeholders who manage budget to allocate some budget to either resolving the issue, or simply accepting the risk.
It’s useful to list impacts to stakeholders separately, such as:
- Users have had their data stolen and sold on the black market, leading to an increase in consumer fraud
- The business owner has lost the trust of their users and thus users are abandoning the service, leading to decreased earnings
- Developers needed to work constantly for long periods of time which forced them to skip personal commitments, leading to a decrease in motivation and productivity
It’s additionally useful to be specific about the financial result of those impacts, such as:
- The business owner is expected to have to pay fines up to ~4 million EU, as well as ongoing civil legal costs of ~2 million EU over the next 12 months.
Look for contributing factors
Now that we’ve got a canonical, detailed record of the issue we can start to establish each of the things that:
- Contributed to the initial issue
- Lengthened the time to recover the issue
Contributing factors can be any number of different issues, from the technical:
- “The disk was full on db01”
- “The network link between db01 and node02 was congested due to automated updates”
To the human:
- “Operator A accidentally ran
rm -rf . /*“ - “Hacker B managed to inject an SQL statement that dropped the table ‘users’”
Or the economic:
- “Project was promised on an impossible timeline and budget”
- “Project scope was increased over time without discussions about the costs of scope creep”
Or the abstract:
- “The understanding of the systems architecture varied between developers and business owners”
- “The risk of breach was not adequately understood by project management”
Each of these issues is fine, and even when they’re assigned to a particular person or team (such as “project management”) it is unreasonable to allocate some fault at that time.
Instead, the issues require a recursive understanding. The common ways of doing this are:
- Continually asking “Why” (5 whys) a particular factor emerged
- Continually asking “How” a particular factor emerged
Such recursive enquiry provides much more insight into each given issue, and can highlight systemic issues within the system that may cause other issues in future. Consider “The disk was full on db01”. This might go through the following steps:
- The disk was full on db01
- Because tooling that down-samples data within that database broke. This set off alarms, but
- Alarms were disabled as that issue was ranked lower priority, and then forgotten about, because
- A feature was overdue and needed to be complete by a given date, because
- Large marketing spend had already been purchased for this date, and
- The developer underestimated the work required to implement the feature
We can see the many factors that gave rise to the fact db01 failed. It was not a singular failure but rather a whole set of process violations that led to this failure.
Lastly, it is sometimes helpful to identity particular markers where complex systems have been known to fail previously. This includes things like:
- Scarcity economics
- Differing conceptual models of software
- Team changes
Look for mitigating factors
As mentioned, complex systems are always in a state of failure. This failure happened now, uniquely, which indicates a series of things happened at this point. But the system copes with this, and perhaps other failures on a regular basis that are similar to this disaster. The mitigating factors of this disaster should be identified as a mechanism to understand how existing prevents are already working, and where to allocate time to continue those. Questions such as:
- Why hadn’t this disaster happened before?
- How did we recover from this disaster so quickly?
The recursive approach applied to the contributing factors works equally well here.
Generate follow up tasks
Finally, once the contributing and mitigating factors have been identified they need to be expressed as work items (tickets or similar) that can be consumed in a predictable way as part of a normal work routine.
These work items are the true value of the post mortem and the post mortem has no value until it causes some change in either the understanding or the process of system development.
Summarise the issue
Lastly, given the complex and thorough nature of these failures not all stakeholders can afford to dive deeply into the issue. However, to maintain some sense of predictability within the business stakeholder (especially at a C level) need some understanding that the issue is understood, and that changes have been made to mitigate this risk going forward.
An abstract that summarises the issue, impact, contributing and mitigating factors and actionable items in ~300 words provides some level of understanding without delving into the complexity.
Follow Up Meetings
Lastly, a post mortem that is not read is of no use. Accordingly once a post mortem has been written it must be followed up until all tasks it outlines have either been completed or marked as “wontfix”.
To this end, immediately upon conclusion of incident response a recurring meeting to discuss the post mortem is created 30 days in the future, repeating monthly. In this meeting all those stakeholders revisit the post mortem, and check whether the work required to prevent this risk in future has been completed in some capacity. If the work has not been completed, the future meeting remains scheduled and the meeting repeats.
Once the post mortem is closed, all future follow up meetings for this post mortem are cancelled. The incident should then go out and celebrate; perhaps go and get a meal, or a coffee.
Lastly, once completed post mortems should be shared at an all hands meeting as a cause for celebration.
In Conclusion
We operate extremely complex software systems in our daily lives, made more complex by the human systems that overlay them. Complex systems are inherently failure prone and that failure can be extraordinarily expensive. Having an incident response process and being disciplined in documenting the results of the incident during this process can help us understand the failure in a much greater depth than otherwise possible. We can do an analysis of these detailed records to identify causal and mitigating factors and make changes to our system such that we reduce the risk of such issues happening again. Follow up meetings provide accountability and ensure that the time spent writing the post mortem goes unwasted.
Thanks
- John Allspaw; Your knowledge here is far superior to mine, and I enjoy learning.